Table of Contents
This is an old revision of the document!
<title> How our clusters work </title>
We expect the HPC clusters users to know what an HPC cluster is and what parallel computing is. As all HPC clusters are different, it is important for any users to have a general understanding of the clusters they are working on, what they offer and what are their limitations.
This section gives an overview of the technical HPC infrastructure and how things work at the University of Geneva. More details can be found in the corresponding sections of this documentation.
The last part of this page gives more details for advanced users.
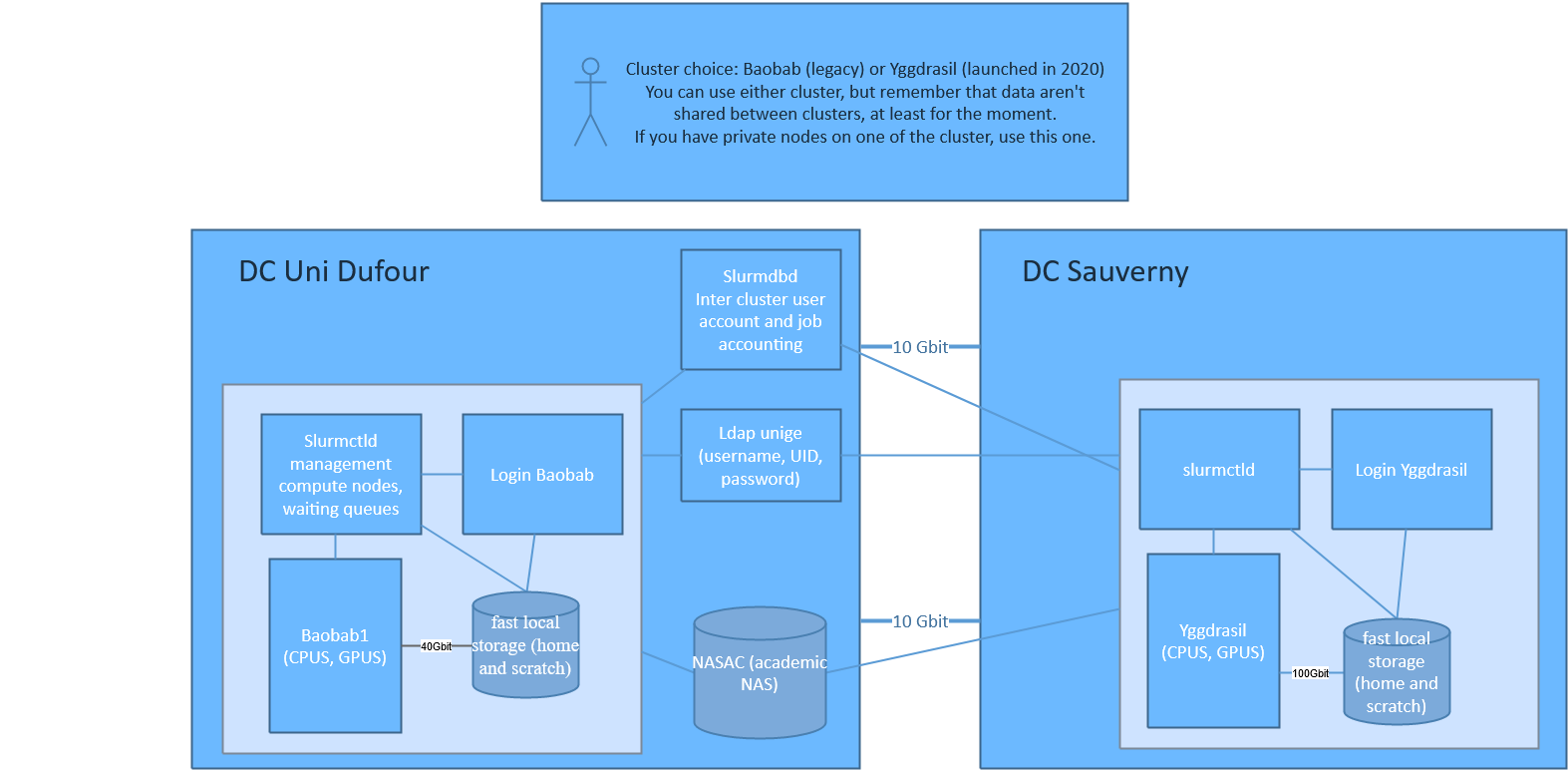
The clusters : Baobab and Yggdrasil
The University of Geneva owns two HPC clusters or supercomputers : Baobab and Yggdrasil.
As for now, they are two completely separated entities, each of them with their own private network, storage, and login node. What is shared is the accounting (user accounts and job usage).
Choose the right cluster for your work:
- You can use both clusters, but try to stick to one of them.
- Use the cluster where the private partition you have access to is located.
- If you need to access other servers not located in Astro, use Baobab to save bandwidth.
- As your data are stored locally on each cluster, avoid to use both clusters if this involves a lot of data moving between cluster.
- Use Yggdrasil if you need newer CPUs, compute nodes with up to 1.5TB of memory, volta GPU.
You can't submit jobs from one cluster to the other one. This may be done in the future.
Boabab is physically located at Uni Dufour in Geneva downtown, while Yggdrasil is located at the Observatory of Geneva in Sauverny.
| cluster name | datacentre | Interconnect | public CPU | public GPU | Total CPU size | Total GPU size |
|---|---|---|---|---|---|---|
| Baobab | Dufour | IB 40GB QDR | ~900 | 0 | ~4200 | 95 |
| Yggdrasil | Astro | IB 100GB EDR | ~3000 | 44 | ~4308 | 52 |
How do our clusters work ?
Overview
Each cluster is composed of :
- a login node (aka headnode) allowing users to connect and submit jobs to the cluster.
- many compute nodes which provide the computing power. The compute nodes are not all identical ; they all provide CPU cores (from 8 to 128 cores depending on the model), and some nodes also have GPUs or more RAM (see below).
- management servers that you don't need to worry about, that's the HPC engineers' job. The management servers are here to provide the necessary services such as all the applications (with EasyBuild / module), Slurm job management and queuing system, ways for the HPC engineers to (re-)deploy compute nodes automatically, etc.
- BeeGFS storage servers which provide “fast” parallel file system to store the data from your
$HOMEand for the scratch data ($HOME/scratch).
All those servers (login, compute, management and storage nodes) :
- run with the GNU/Linux distribution CentOS.
- are inter-connected on high speed InfiniBand network
- 40Gbit/s (QDR) for Baobab.
- 100Gbit/s (EDR) for Yggdrasil.
In order to provide hundreds of software and versions, we use EasyBuild / module. It allows you to load the exact version of a software/library that is compatible with your code. Learn more about EasyBuild/module
When you want to use some cluster's resources, you need to connect to the login node and submit a job
to Slurm which is our job management and queuing system. The job is submitted with an sbatch
script (a Bash/shell script with special instructions for Slurm such as how many CPU you need,
which Slurm partition to use how long your script will run and how to execute your code).
Slurm will place your job in a queue with other users' jobs, and find the fastest way to provide the
resources you asked for. When the resources are available, your job will start.
Learn more about Slurm
One important note about Slurm is the concept of partition. When you submit a job, you have to specify a partition that will give you access to some specific resources. For instance, you can submit a job that will use only CPU or GPU nodes.
Private nodes
Research groups can buy “private” nodes to add in our clusters, which means their research group has a private partition with a higher priority to use those specific nodes (less waiting time) and they can run their jobs for a longer time (7 days instead of 4 for public compute nodes).
Rules:
- The compute node remains the research group property
- The compute node has a three years warranty. If it fails after the warranty expiration, the repair cost is to be paid at 100% by the research group
- The research groups hasn't an admin right on it
- The compute node is installed and maintained by the HPC team in the same way as the other compute nodes
- The HPC team can decide to decommission the node when it is too old but the hardware will be in production for at least four years
See the partitions section to have more details about the integration of your private node in the cluster.
Current price for a compute node is:
– AMD –
- 2 x 64 Core AMD EPYC 7742 2.25GHz Processor
- 512GB DDR4 3200MHz Memory (16x32GB)
- ~ 13'700 CHF TTC
– Intel –
- 2 x 18 Core Intel Xeon Gold 6240 2.6GHz Processor
- 384GB DDR4 2933MHz Memory (12x32GB)
- ~ 8'070 CHF TTC
– GPU A100 with AMD –
- 1 x 64 Core AMD EPYC 7742 2.25GHz Processor
- 256GB DDR4 3200MHz ECC Server Memory (8x 32GB / 0 free slots)
- 1 x 1.92TB SATAIII Intel 24×7 Datacenter SSD (6.5PB written until warranty end)
- 1 x nVidia Tesla A100 40GB PCIe GPU passive cooled (max. 4 GPUs possible)
- ~ 24'300 CHF TTC
- ~ 11'270 CHF TTC per extra GPU
– GPU RTX3090 with AMD –
- 2 x 64 Core AMD EPYC 7742 2.25GHz Processor (Turbo up to 3.4GHz)
- 512GB DDR4 3200MHz ECC Server Memory
- 8 x nVidia RTX 3090 24GB Graphics Controller
- ~ 42'479 CHF TTC
Right now, we have a special funding that will do a matching fund (50/50).
How do I use your clusters ?
Everyone has different needs for their computation. A typical example of usage of the cluster would consists of these steps :
- connect to the login node
- this will give you access to the data from your
$HOMEdirectory - execute an sbatch script which will request resources to Slurm for the estimated runtime (i.e. : 16 CPU cores, 8 GB RAM for up to 7h on partition “shared-cpu”). The sbatch will contain instructions/commands :
- for Slurm scheduler to access compute resources for a certain time
- to load the right application and libraries with
modulefor your code to work - on how to execute your application.
- the Slurm job will be placed in the Slurm queue
- once the requested resources are available, your job will start and be executed on one or multiple compute nodes (which can all access the BeeGFS
$HOMEand$HOME/scratchdirectories). - all communication and data transfer between the nodes, the storage and the login node go through the InfiniBand network.
If you want to know what type of CPU and architecture is supported, check the section For Advanced users.
For advanced users
Infrastructure schema

Compute nodes
Both clusters contain a mix of “public” nodes provided by the University of Geneva, a “private” nodes in general paid 50% by the University and 50% by a research group for instance. Any user of the clusters can request compute resources on any node (public and private), but a research group who owns “private” nodes has a higher priority on its “private” nodes and can request a longer execution time.
Baobab
CPUs on Baobab
Since our clusters are regularly expanded, the nodes are not all from the same generation. You can see the details in the following table.
| Generation | Model | Freq | Nb cores | Architecture | Nodes | Extra flag |
|---|---|---|---|---|---|---|
| V2 | X5650 | 2.67GHz | 12 cores | “Westmere-EP” (32 nm) | node[076-153] | |
| V3 | E5-2660V0 | 2.20GHz | 16 cores | “Sandy Bridge-EP” (32 nm) | node[001-056,058] | |
| V3 | E5-2670V0 | 2.60GHz | 16 cores | “Sandy Bridge-EP” (32 nm) | node[059-062,067-070] | |
| V3 | E5-4640V0 | 2.40GHz | 32 cores | “Sandy Bridge-EP” (32 nm) | node[057,186,214-215] | |
| V4 | E5-2650V2 | 2.60GHz | 16 cores | “Ivy Bridge-EP” (22 nm) | node[063-066,071,154-172] | |
| V5 | E5-2643V3 | 3.40GHz | 12 cores | “Haswell-EP” (22 nm) | gpu[002,012] | |
| V6 | E5-2630V4 | 2.20GHz | 20 cores | “Broadwell-EP” (14 nm) | node[173-185,187-201,205-213] | |
| gpu[004-010] | ||||||
| V6 | E5-2637V4 | 3.50GHz | 8 cores | “Broadwell-EP” (14 nm) | node[218-219] | HIGH_FREQUENCY |
| V6 | E5-2643V4 | 3.40GHz | 12 cores | “Broadwell-EP” (14 nm) | node[202,204,216-217] | HIGH_FREQUENCY |
| V6 | E5-2680V4 | 2.40GHz | 28 cores | “Broadwell-EP” (14 nm) | node[203] | |
| V7 | EPYC-7601 | 2.20GHz | 64 cores | “Naples” (14 nm) | gpu[011] | |
| V8 | EPYC-7742 | 2.25GHz | 128 cores | “Rome” (7 nm) | gpu[013-014] | |
| V9 | GOLD-6240 | 2.60GHz | 36 cores | “Cascade Lake” (14 nm) | node[265-272] |
The “generation” column is just a way to classify the nodes on our clusters. In the following table you can see the features of each architecture.
| MMX | SSE | SSE2 | SSE3 | SSSE3 | SSE4.1 | SSE4.2 | AVX | F16C | AVX2 | FMA3 | NB AVX-512 FMA | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Westmere-EP | YES | YES | YES | YES | YES | YES | YES | NO | NO | NO | NO | |
| Sandy Bridge-EP | YES | YES | YES | YES | YES | YES | YES | YES | NO | NO | NO | |
| Ivy Bridge-EP | YES | YES | YES | YES | YES | YES | YES | YES | YES | NO | NO | |
| Haswell-EP | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | NO | |
| Broadwell-EP | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |
| Naples | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |
| Rome | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |
| Casake Lake | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | 2 |
GPUs on Baobab
In the following table you can see which type of GPU is available on Baobab.
| GPU model | Architecture | Mem | Compute Capability | Slurm resource | Nb per node | Nodes |
|---|---|---|---|---|---|---|
| Titan X | Pascal | 12GB | 6.1 | titan | 6 | gpu[002] |
| P100 | Pascal | 12GB | 6.0 | pascal | 6 | gpu[004] |
| P100 | Pascal | 12GB | 6.0 | pascal | 5 | gpu[005] |
| P100 | Pascal | 12GB | 6.0 | pascal | 8 | gpu[006] |
| P100 | Pascal | 12GB | 6.0 | pascal | 4 | gpu[007] |
| Titan X | Pascal | 12GB | 6.1 | titan | 8 | gpu[008] |
| Titan X | Pascal | 12GB | 6.1 | titan | 8 | gpu[009-010] |
| RTX 2080 Ti | Turing | 11GB | 7.5 | rtx | 2 | gpu[011] |
| RTX 2080 Ti | Turing | 11GB | 7.5 | rtx | 8 | gpu[012-014] |
Yggdrasil
CPUs on Yggdrasil
Since our clusters are regularly expanded, the nodes are not all from the same generation. You can see the details in the following table.
| Generation | Model | Freq | Nb cores | Architecture | Nodes | Extra flag |
|---|---|---|---|---|---|---|
| V7_INTEL | XEON_GOLD_6240 | 2.60GHz | 36 cores | “Intel Xeon Gold 6240 CPU @ 2.60GHz” | cpu[001-111] | |
| V7_INTEL | XEON_GOLD_6244 | 3.60GHz | 16 cores | “Intel Xeon Gold 6244 CPU @ 3.60GHz” | cpu[112-115] | |
| V3_AMD | AMD_EPYC_7742 | 2.25GHz | 128 cores | “AMD EPYC 7742 64-Core Processor” | cpu[116-119] | |
| V7_INTEL | XEON_SILVER_4208 | 2.10GHz | 16 cores | “Intel Xeon Silver 4208 CPU @ 2.10GHz” | gpu[001-006,008] | |
| V7_INTEL | XEON_GOLD_6234 | 3.30GHz | 16 cores | “Intel Xeon Gold 6234 CPU @ 3.30GHz” | gpu[007] |
The “generation” column is just a way to classify the nodes on our clusters. In the following table you can see the features of each architecture.
| SSE4.2 | AVX | AVX2 | NB AVX-512 FMA | |
|---|---|---|---|---|
| Intel Xeon Gold 6244 | YES | YES | YES | 2 |
| Intel Xeon Gold 6240 | YES | YES | YES | 2 |
| Intel Xeon Gold 6234 | YES | YES | YES | 2 |
| Intel Xeon Silver 4208 | YES | YES | YES | 1 |
Click here to Compare Intel CPUS.
GPUs on Yggdrasil
In the following table you can see which type of GPU is available on Yggdrasil.
| GPU model | Architecture | Mem | Compute Capability | Slurm resource | Nb per node | Nodes | Peer access between GPUs |
|---|---|---|---|---|---|---|---|
| Titan RTX | Turing | 24GB | 7.5 | rtx | 8 | gpu[001,002,004] | NO |
| Titan RTX | Turing | 24GB | 7.5 | rtx | 6 | gpu[003,005] | NO |
| Titan RTX | Turing | 24GB | 7.5 | rtx | 4 | gpu[006,007] | NO |
| V100 | Volta | 32GB | 7.0 | v100 | 1 | gpu[008] | YES |
